Recommender Systems — User-Based and Item-Based Collaborative Filtering
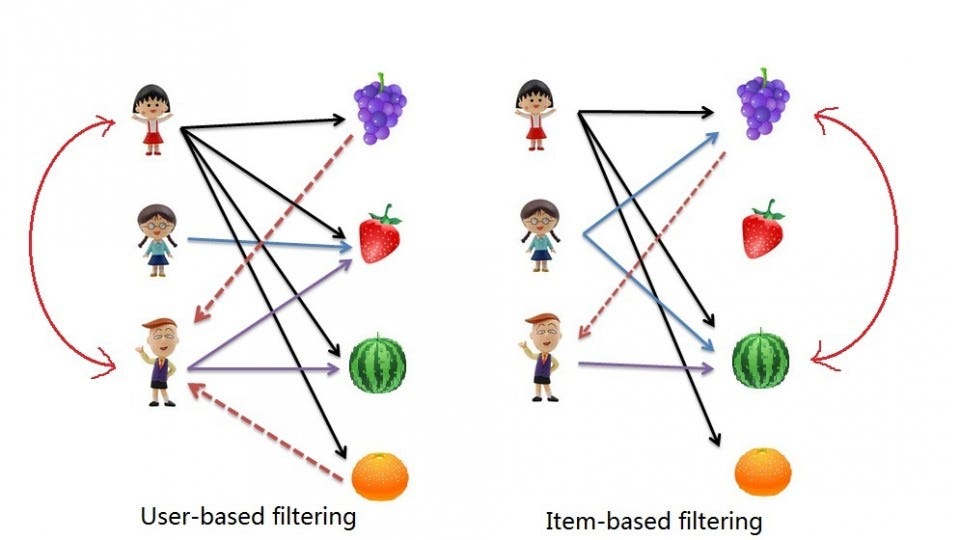
This is part 2 of my series on Recommender Systems. The last post was an introduction to RecSys. Today I’ll explain in more detail three types of Collaborative Filtering: User-Based Collaborative Filtering (UB-CF) and Item-Based Collaborative Filtering (IB-CF).
Let’s begin.
User-Based Collaborative Filtering (UB-CF)
Imagine that we want to recommend a movie to our friend Stanley. We could assume that similar people will have similar taste. Suppose that me and Stanley have seen the same movies, and we rated them all almost identically. But Stanley hasn’t seen ‘The Godfather: Part II’and I did. If I love that movie, it sounds logical to think that he will too. With that, we have created an artificial rating based on our similarity.
Well, UB-CF uses that logic and recommends items by finding similar users to the active user (to whom we are trying to recommend a movie). A specific application of this is the user-based Nearest Neighbor algorithm. This algorithm needs two tasks:
1.Find the K-nearest neighbors (KNN) to the user a, using a similarity function wto measure the distance between each pair of users:
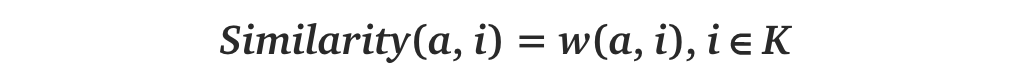
2.Predict the rating that user a will give to all items the k neighbors have consumed but a has not. We Look for the item j with the best predicted rating.
In other words, we are creating a User-Item Matrix, predicting the ratings on items the active user has not see, based on the other similar users. This technique is memory-based.
PROS:
- Easy to implement.
- Context independent.
- Compared to other techniques, such as content-based, it is more accurate.
CONS:
- Sparsity: The percentage of people who rate items is really low.
- Scalability: The more K neighbors we consider (under a certain threshold), the better my classification should be. Nevertheless, the more users there are in the system, the greater the cost of finding the nearest K neighbors will be.
- Cold-start: New users will have no to little information about them to be compared with other users.
- New item: Just like the last point, new items will lack of ratings to create a solid ranking (More of this on ‘How to sort and rank items’).
Item-Based Collaborative Filtering (IB-CF)
Back to Stanley. Instead of focusing on his friends, we could focus on what items from all the options are more similar to what we know he enjoys. This new focus is known as Item-Based Collaborative Filtering (IB-CF).
We could divide IB-CF in two sub tasks:
1.Calculate similarity among the items:
- Cosine-Based Similarity
- Correlation-Based Similarity
- Adjusted Cosine Similarity
- 1-Jaccard distance
2.Calculation of Prediction:
- Weighted Sum
- Regression
The difference between UB-CF and this method is that, in this case, we directly pre-calculate the similarity between the co-rated items, skipping K-neighborhood search.
Slope One
Slope One is part of the Item-Based Collaborative Filtering family, introduced in a 2005 paper by Daniel Lemire and Anna Maclachlan called Slope One Predictors for Online Rating-Based Collaborative Filtering.
The main idea behind this model is the following:
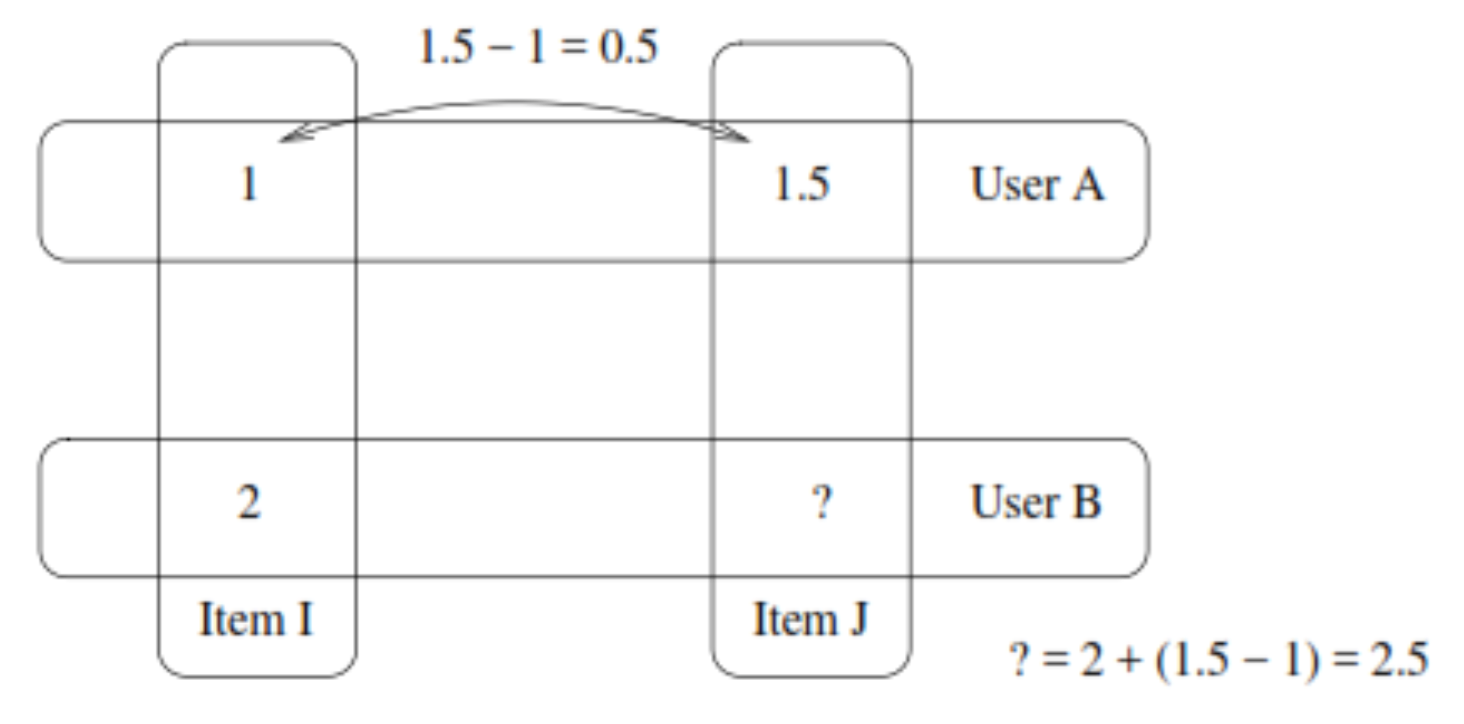
Suppose we have two different users: Aand B. Also, we have item I and item J. User A rated item I with 1 star and the item J with 1.5. If the User B rated Item Iwith a 2. We can make the assumption that the difference between both items will be the same as User A. With this in mind, User B would rate Item J as: 2+ (1,5–1) = 2,5
The authors focus on 5 objectives:
1. Easy to implement and maintain.
2. Updatable online: new ratings should change predictions quickly.
3. Efficient at the time of consultation: storage is the main cost.
4. It works with little user feedback.
5. Reasonably accurate, within certain ranges in which a small gain in accuracy does not mean a great sacrifice of simplicity and scalability.
1. Easy to implement and maintain.
2. Updatable online: new ratings should change predictions quickly.
3. Efficient at the time of consultation: storage is the main cost.
4. It works with little user feedback.
5. Reasonably accurate, within certain ranges in which a small gain in accuracy does not mean a great sacrifice of simplicity and scalability.
Recap
We saw User-Based and Item-Based Collaborative Filtering. The first has a focus on filling an user-item matrix and recommending based on the users more similar to the active user. On the other hand, IB-CF fills a Item-Item matrix, and recommends based on similar items.
It is hard to explain all these subjects briefly, but understanding them is the first step to getting deeper into RecSys
Comments
Post a Comment